Representativeness bias in artificial intelligence

Binaire, le blog informatique du Monde, a publié un article de Nathan Noiry, membre de datacraft, intitulé “Des biais de représentativité en intelligence artificielle“. Il évoque un atelier datacraft qu’il a animé avec Yannick Guyonvarch. L’objectif était d’introduire la notion de “biais de représentativité” et de proposer une méthodologie pour les détecter et les corriger. L’article a été rédigé avec le concours de Yannick Guyonvarch et avec les conseils de Victor Storchan, également membres du Club.
Des biais de représentativité en intelligence artificielle
En janvier 2020, l’erreur d’un algorithme de reconnaissance faciale des services de police de Détroit (Michigan) a conduit à l’arrestation injustifiée de Robert Williams [1], [2]. Identifié à tort avec un voleur de montres, il passera trente heures en détention. Si la confiance aveugle des policiers dans leur technologie explique en grande partie l’injustice (une simple vérification humaine aurait sans doute suffi à éviter l’incident), cette faute a permis de mettre en lumière les biais raciaux des algorithmes de reconnaissance faciale. Malgré leur redoutable précision biométrique, ces derniers ont en effet tendance à se tromper plus souvent sur certains sous-groupes démographiques, les noirs et les femmes notamment, comme le décrit le rapport [3] du National Institute of Standard and Technology. Au delà de cet exemple frappant, la problématique des biais est aujourd’hui centrale dans le développement des outils d’intelligence artificielle : leur présence insidieuse conduit bien souvent à des prises de décisions discriminatoires et font d’eux un enjeu majeur pour les années à venir. Voir par exemple le désormais célèbre ouvrage Weapons of Math Destruction de Cathy O’Neil.
Qu’est-ce qu’un biais ?
Le terme est omniprésent mais parfois mal compris tant il recouvre de réalités différentes. Les auteurs de l’article de synthèse Algorithmes : Biais, Discrimination et Équité [4] définissent un biais comme une « déviation par rapport à un résultat censé être neutre, loyal ou encore équitable » et en distinguent deux grandes familles. Les biais cognitifs, d’abord, qui irriguent tous les autres : biais de confirmation, tendance à détecter de fausses corrélations entre évènements… Nous renvoyons le lecteur au livre Thinking, Fast and Slow de Daniel Kahneman décrivant ses nombreux travaux avec Amos Tversky sur le sujet. La deuxième grande famille de biais est de nature statistique et correspond à ce que l’on appelle communément biais des données ou biais de représentativité. Ces derniers désignent une situation d’inadéquation entre données utilisées pour l’entraînement d’un algorithme et données cibles sur lesquelles l’algorithme sera déployé. Un tel exemple est fourni par la surreprésentation des afro-américains dans les bases de données de photos d’identité judiciaires américaines [5], expliquant en partie les biais raciaux mentionnés précédemment.
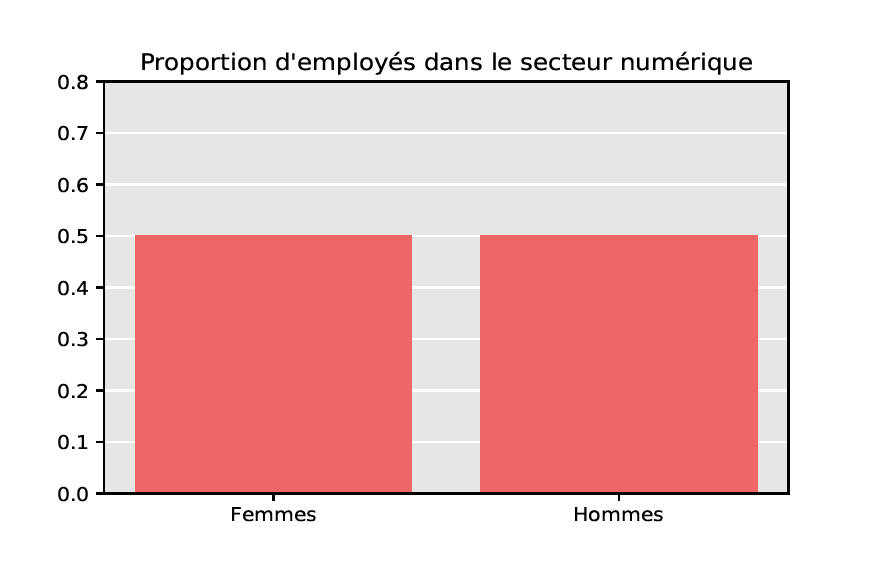
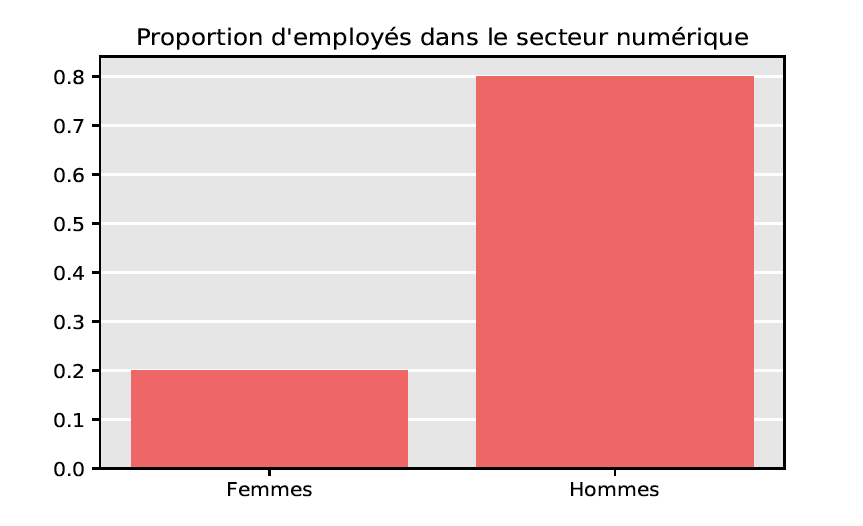
Biais et équité
À ce stade, il nous semble important de souligner que les problèmes de représentativité se superposent seulement en partie avec les problèmes d’équité. Afin d’illustrer notre propos, imaginons vouloir développer un algorithme de gestion de carrière dans le secteur numérique en France, où la part des femmes est d’environ 20%. À cet effet, on collecte des données d’entraînement en réalisant un sondage auprès de certains employés de ce secteur : ci-dessus, on distingue deux situations (fictives) correspondant respectivement à une proportion de femmes de 20% ou de 50% dans l’échantillon interrogé. Le premier échantillon, non-équitable du point de vue de la parité homme/femme, est cependant représentatif puisque la proportion des femmes coïncide avec celle de la population totale. Au contraire, le deuxième échantillon, bien que paritaire, n’est pas représentatif. De cet exemple, on retiendra qu’un biais de représentativité se définit par rapport à une population cible observée, tandis qu’un biais inhérent (de genre, de race…) se définit par rapport à des caractéristiques cibles que l’on souhaite atteindre et pouvant différer de celles de la population observée.
D’où viennent les biais ?
La problématique des biais n’est pas nouvelle : les instituts de sondages s’escriment depuis des décennies à concevoir des enquêtes permettant d’obtenir un échantillon représentatif de la population étudiée. Elle a néanmoins pris une tournure plus systématique depuis l’avènement du Big Data. Notre faculté d’acquérir et de stocker des bases de données toujours plus massives a en effet opéré un changement de paradigme dans leur utilisation : l’information est aujourd’hui disponible avant même de se poser une question spécifique. Cet état de fait permet bien souvent au praticien de s’affranchir de la délicate étape (souvent coûteuse) de collecte des données, mais l’absence de contrôle sur le processus d’acquisition l’expose à de nombreux problèmes de représentativité. À titre d’exemple, une entreprise agroalimentaire possédant un modèle pré-entraîné sur le marché français et souhaitant développer son activité en Chine prendra le risque d’effectuer de mauvaises prédictions du fait d’une différence significative entre les comportements des consommateurs.
Modéliser les biais
Le processus même de collecte des données, en ce qu’il déforme bien souvent les caractéristiques de la population d’intérêt, peut altérer l’information que l’on souhaite acquérir. Les données observées ne sont alors que des versions imparfaites des données cibles originelles, immaculées mais inaccessibles. Aussi, la première étape de l’étude statistique des biais consiste à modéliser de manière adéquate les mécanismes de sélection à l’œuvre, miroirs déformants responsables de la transformation des données. De manière schématique, on en distinguera deux grandes instances.
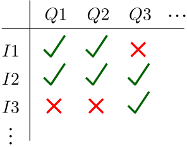 1. La sélection stricte, qui permet principalement de modéliser l’absence de réponse dans des sondages. Celle-ci est généralement endogène : un individu ne répond pas à une ou des questions selon ses propres caractéristiques. Par exemple, l’INSEE reporte un faible taux de réponse (d’environ 50%) parmi les petites et moyennes entreprises interrogées lors de son enquête annuelle sur la santé économique française [7], quand les grandes entreprises répondent systématiquement.
1. La sélection stricte, qui permet principalement de modéliser l’absence de réponse dans des sondages. Celle-ci est généralement endogène : un individu ne répond pas à une ou des questions selon ses propres caractéristiques. Par exemple, l’INSEE reporte un faible taux de réponse (d’environ 50%) parmi les petites et moyennes entreprises interrogées lors de son enquête annuelle sur la santé économique française [7], quand les grandes entreprises répondent systématiquement.
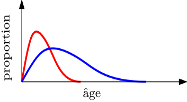 2. La sélection douce, qui correspond à une déformation continue des données. La courbe de répartition de l’âge des répondants à une enquête en ligne (en rouge) aura par exemple tendance à être décalée vers les jeunes, comparativement à la courbe de répartition des âges de la population de référence (en bleu). Ce phénomène est également présent, de manière plus pernicieuse, dans le secteur industriel où le vieillissement du matériel électronique (capteurs aéronautiques de pression, par exemple) peut engendrer de légères déformations dans les mesures effectuées.
2. La sélection douce, qui correspond à une déformation continue des données. La courbe de répartition de l’âge des répondants à une enquête en ligne (en rouge) aura par exemple tendance à être décalée vers les jeunes, comparativement à la courbe de répartition des âges de la population de référence (en bleu). Ce phénomène est également présent, de manière plus pernicieuse, dans le secteur industriel où le vieillissement du matériel électronique (capteurs aéronautiques de pression, par exemple) peut engendrer de légères déformations dans les mesures effectuées.
Dans le cas de la sélection stricte, on modélise la propension d’un individu à répondre au sondage. Pour la sélection douce, on modélisera plutôt la fonction de déformation, dans notre exemple, le ratio entre courbe rouge et courbe bleue. Le choix du modèle est une étape cruciale et doit être effectué en étroite collaboration avec des experts du domaine afférent.
Peut-on détecter et corriger les biais ?
Une fois passée l’étape de modélisation, il est possible de tester la pertinence du modèle sélectionné. C’est à ce stade que la connaissance d’information auxiliaire sur la population cible s’avère déterminante. Celle-ci prend souvent la forme de caractéristiques moyennes issues d’enquêtes pré-existantes et de large ampleur – il est par exemple aisé d’obtenir des informations agrégées telles que l’âge moyen ou le salaire moyen, tandis que les données individuelles sont parfois difficiles d’accès pour des raisons de confidentialité. La méthode la plus simple de détection des biais consiste alors à comparer les moyennes de la base de données à disposition avec les moyennes cibles de la population d’intérêt. D’autres techniques plus élaborées peuvent être mises en place, mais leurs descriptions dépassent largement le cadre de cet article. Une fois qu’un biais est détecté, il est possible de le corriger, au moins en partie. Nous nous bornerons à mentionner les deux méthodes les plus utilisées en pratique. La première, appelée imputation, est spécifique à la sélection stricte et consiste à remplir les réponses absentes dans un questionnaire – en ajoutant la réponse la plus probable au vu des réponses des autres individus, par exemple. La seconde méthode, plus adaptée à la sélection douce, consiste à affecter un poids à chacune des données de manière à ce que les moyennes re-pondérées qui en résultent s’approchent des moyennes auxiliaires cibles. Avec Patrice Bertail, Stéphan Clémençon et Yannick Guyonvarch, nous avons récemment proposé une telle méthode de re-pondération [7].
Et pour conclure
Les biais de représentativité sont omniprésents et peuvent être à l’origine de nombreuses erreurs, trop souvent discriminatoires. Développer une intelligence artificielle éthique et de confiance passera nécessairement par une prise en charge systématique de ces biais, dont l’importance grandit avec l’avènement de l’ère des données massives. De nombreuses méthodes existent déjà, mais les problématiques de représentativité restent largement ouvertes et demeurent un sujet de recherche actif. Un changement de point de vue est d’ailleurs en cours et de nombreux chercheurs (voir notamment [8]) incitent à recentrer les efforts sur la compréhension fine des données plutôt que sur le développement de modèles algorithmiques toujours plus coûteux.
Nathan Noiry, Télécom Paris

Postscriptum : Merci à Yannick Guyonvarch ainsi qu’à toute l’équipe de datacraft et à Victor Storchan pour ses précieux conseils.
Article publié le 31 août 2021
Pour aller plus loin
[1] Un américain noir arrêté à tort à cause de la technologie de reconnaissance faciale, Le Monde ; 2020.
[2] Wrongfully Accused by an Algorithm, New York Times ; 2020.
[3] Face Recognition Vendor Test, Part 3: Demographic Effects, Grother, Ngan, Hanaoka, 2019.
[4] Algorithmes : Biais, Discrimination et Équité, Bertail, Bounie, Clémençon, Waelbroeck ; 2019.
[5] Facial Recognition Is Accurate, If you’re a White Guy, New York Times ; 2018.
[6] La correction de la non-réponse par repondération, Thomas Deroyon (Insee) ; 2017.
[7] Learning from Biased Data: A Semi-Parametric Approach, International Conference on Machine Learning ; Bertail, Clémençon, Guyonvarch, Noiry ; 2021.
[8] Andrew Ng Launches A Campaign For Data-Centric AI, Forbes ; 2021.
Recent Comments